


支持多粒度稀疏的AI训练芯片
清华大学集成电路学院魏少军、尹首一教授团队在人工智能(AI)训练芯片方向取得突破。该团队设计的AI训练芯片Trainer,以实现场景自适应的高能效模型训练为目标,突破传统AI训练芯片学习机制和电路实现的技术局限性,为高效AI模型训练提供了坚实的硬件基础。2022年5月5日,该研究成果以"Trainer: An Energy-Efficient Edge-Device Training Processor Supporting Dynamic Weight Pruning"为题发表于集成电路领域顶级期刊IEEE Journal of Solid-State Circuits (JSSC)。
近年来,AI作为一项影响深远的颠覆性技术,在机器翻译、人机交互、医学诊断、自动驾驶等多个领域取得了突破性进展。AI技术的成功高度依赖于“算法、算力、数据”三个关键要素。AI算法的参数量和训练数据量爆炸式增长,给AI芯片带来巨大的能耗,严重制约AI技术的持续发展和广泛应用。例如,迄今最强的自然语言处理模型GPT-3具有1750亿参数,其训练所用的数据量高达45TB,需要在微软Azure云平台的1万颗GPU训练30天,消耗1.16×1013 J的能量(约为3000个成年人1年的能量消耗)。因此,提升AI模型训练的能效成为实现AI持续发展必须克服的严峻挑战。然而,基于传统训练机制的AI芯片难以解决这一问题。通常,AI模型的训练包含两个阶段。首先,需要基于特定数据集在AI芯片上对模型所有参数进行训练,以达到理想的推理精度。而后,利用模型的冗余性,对较小的参数进行剪枝和再训练,减小模型规模。这种机制需要首先对所有参数训练更新,消耗大量的训练时间和能量。
为了避免对冗余参数训练导致的时间和能量浪费,Trainer采用边更新边剪枝的训练机制,其流程如图1所示。面对不同复杂度的应用场景,Trainer在训练迭代过程中,基于当前训练精度自适应生长或修剪网络连接。在每次迭代过程中,Trainer只使用和更新保留的参数,避免冗余参数的相关计算,从而大幅减少计算和访存开销,高效适应多样化应用场景。

图1. 基于动态权重剪枝的稀疏训练机制。
动态剪枝可有效减少训练计算量,需要设计全新的训练芯片架构从而充分利用其动态权重稀疏特性。Trainer包含三个关键技术,实现对动态权重稀疏的高效利用,其整体架构如图2所示。首先,Trainer包含系统级冗余计算预测单元,通过剖析训练过程中结构化权重稀疏在前馈计算、反向传播和权重更新三个阶段的全局作用,预测并移除训练阶段中的隐式冗余计算。不同于显式冗余计算,隐式冗余计算的输入值、权重值以及输出值均不为0,但对训练无效。其次,Trainer针对不规则的非结构化稀疏权重,采用实时复用检测、乱序稀疏压缩的计算数据流,动态适配权重复用情况,解决不规则权重稀疏导致的数据复用不均衡问题,提高训练过程中的硬件资源利用率。最后,Trainer通过提取BN计算公因子,并基于公因子重组BN公式的方式,解耦BN计算的串行数据依赖,实现并行正反向BN计算,减少训练过程中访存开销。解决卷积层和全连接层运算量随动态剪枝显著减小后,串行BN计算时重复数据访存导致的训练瓶颈。
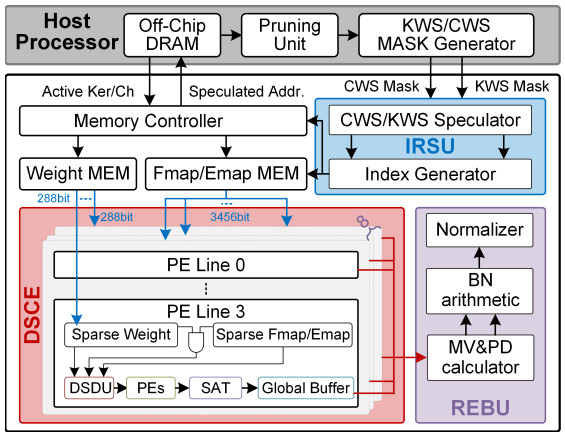
图2. Trainer芯片的整体架构。
Trainer芯片版图和性能总结如图3所示,采用28 nm CMOS工艺实现,在FP8的计算精度下,Trainer的峰值能效为276.55TFLOPS/W,是NVIDIA A100 GPU的177.3倍。相比于GPU的训练后剪枝的模型进化机制,Trainer可以减少60倍的训练时间和1500倍的训练能量。团队此次研究成果,从训练机制和硬件架构角度为现有AI训练芯片带来了突破,显著增强了芯片面向不同任务时的学习效率,大幅减少芯片训练的时间和能量开销, 为AI训练芯片的演进开拓了新方向。
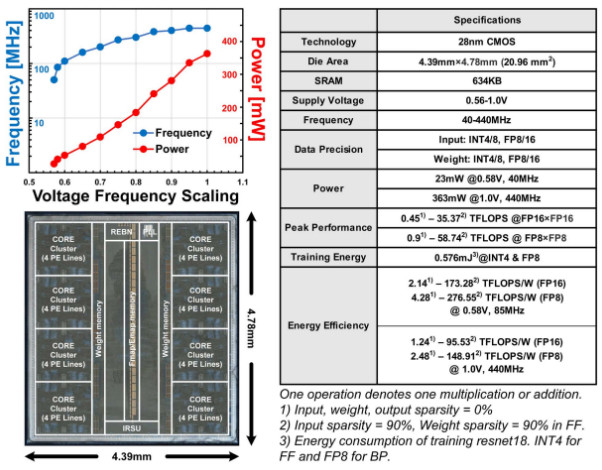
图3. Trainer芯片的版图与性能总结。
来源:半导体学报公众号

